Расширенное руководство по внутренним ссылкам
Аксиомы о внутренних ссылках
SEO – это уникальная сфера с неоднозначной информацией и быстрыми изменениями. Если вы не будете постоянно бросать вызов устоявшимся убеждениям, то отстанете от остальных. Вот почему я создал это руководство на основе аксиом.
Я перечислю доказательства (в основном из заявлений Google) за и против каждой аксиомы, чтобы либо подтвердить, либо опровергнуть ее. Жизнь не состоит только из черных и белых цветов. Многое зависит от контекста. Также я поделюсь своим личным опытом, к которому следует относиться с долей скепсиса.
Аксиома: «Не следует ставить слишком много внешних ссылок»
Слишком большое количество исходящих ссылок снижает вероятность высокого ранжирования веб-страницы по целевому ключевому слову. В области SEO-оптимизации остается некоторая путаница, потому что с годами Google изменил свою позицию по этому вопросу.
Правда: в руководстве для веб-мастеров Google рекомендуется «ограничивать количество ссылок на странице разумным числом (не больше нескольких тысяч)».
Неверно:в старом сообщении в блоге Google от 2008 года говорится: «Слишком большое количество ссылок на одной странице сбивает посетителей с толку (обычно мы рекомендуем веб-мастерам добавлять не более 100 ссылок на одной странице)». Обратите внимание, что сейчас информация о сотне ссылок была удалена из статьи.
В видео 2022 года Мэтт Каттс подтвердил, что старая рекомендация устарела. Некоторые страницы часто содержат 200, 300, 400 и больше ссылок – главное, чтобы они были полезными.
Неверно: Джон Мюллер упомянул, что исходящие ссылки не понижают PageRank.
«На некоторых сайтах присутствует множество ссылок, а на других их может быть мало, но все они могут ранжироваться в поиске. Можно провести тестирование – найдите 5000 случайных исходящих ссылок и изучите, как они влияют на страницы, с которых проводится перенаправление пользователя. Скорее всего, вы обнаружите, что даже индейские танцы для вызова дождя в результате оказывают более сильное влияние.»
Неверно: Джон также говорил, что большое количество ссылок – менее серьезная проблема, чем недостаток высококачественного контента.
Личный опыт: в 2022 году я работал с крупной публичной компанией над их удалением из фильтра Google Panda. У них были тысячи страниц с более чем 2000 исходящих ссылок, но на них не было никакого контента. Сокращение этих хабовых страниц и добавление контента вернуло сайт к исходному уровню (он потерял около 70% трафика). После слов Джона становится понятно, почему сработало добавление контента и удаление лишних ссылок.
Аксиома: «Вы должны ссылаться на авторитетные источники»
Я думаю, эта аксиома родилась из идеи о плохом/хорошем соседстве сайтов. Она заключается в том, что входящие и исходящие ссылки на ваш сайт со страниц с низким качеством контента/рассылкой спама/нарушениями правил относят вас к «плохому соседству» и понижают в ранжировании.
За: в блоге Google есть старая запись 2008 года, в которой говорится, что исходящие ссылки могут влиять на уровень доверия к сайту. Однако, в этой же статье говорится о том, что более сотни исходящих ссылок могут привести к проблемам. Вероятно, эта информация устарела.
Также эта статья утверждает, что «[…] с точки зрения поисковой системы, спам в комментариях может поместить ваш сайт в плохое соседство, а не в категорию проверенных законных ресурсов».
Личный опыт: я никогда не видел, чтобы кто-то это тестировал, и не замечал повышения рейтинга от ссылок на более авторитетные источники. При этом мне кажется бессмысленным делать ссылки на авторитетный источник только ради того, чтобы они были. Я бы не рекомендовал так делать. Тем не менее, я стараюсь делать ссылки на другие сайты, когда они по-настоящему полезны.
Аксиома: «Вы должны использовать в тексте ссылки (анкоре) ключевое слово, по которому хотите ранжироваться»
Анкор – это важный фактор для поисковых систем, с помощью которого можно понять тему страницы. Идея, лежащая в основе этой аксиомы, заключается в использовании одного и того же текста ссылки для повышения релевантности ключевого слова в Google.
Правда: Google четко рекомендует «Выбирать описательный текст» в своем руководстве по SEO для начинающих и советует «тщательно продумывать тексты ссылок».
Видимый текст ссылки помогает пользователям и Google понять содержание страницы. Ссылки на странице могут быть внутренними (указывают на другие страницы сайта) или внешними (ведут на другие сайты). В любом случае, чем понятнее текст ссылки, тем проще пользователям ориентироваться на сайте, а поисковым системам легче понять, о чем страница, на которую ведет ссылка.
Руководство по поисковой оптимизации для начинающих
Переспам
Я учился у Антона Маркина и состою в его закрытом SEO-сообществе, поэтому у меня есть доступ к его закрытому инструменту «Гибридный анализ релевантности (ГАР)». Я проверял страницы с его помощью. Но если у вас ГАРа нет, то можно воспользоваться Миратекстом, инструмент «Полный семантический анализ текста».
И ГАР, и Миратекст сравнивают текст на сайте с текстами конкурентов в ТОПе Яндекса, анализируют релевантность сайта и указывают на слабые места. Но ГАР анализирует подробнее, и глубже делает выборку сайтов для анализа, дополнительно показывает рекомендации по улучшению сайта.
В том числе инструменты показывают облака запросов по странице и по тегу <a>. Это важно, потому что некоторые слова лучше «зашивать» в ссылки на странице (меню, теги и т. д.), а некоторые — в текст. Поэтому облако запросов составляется раздельно по этим показателям.
Если облако маленькое, то релевантность страницы слабая.

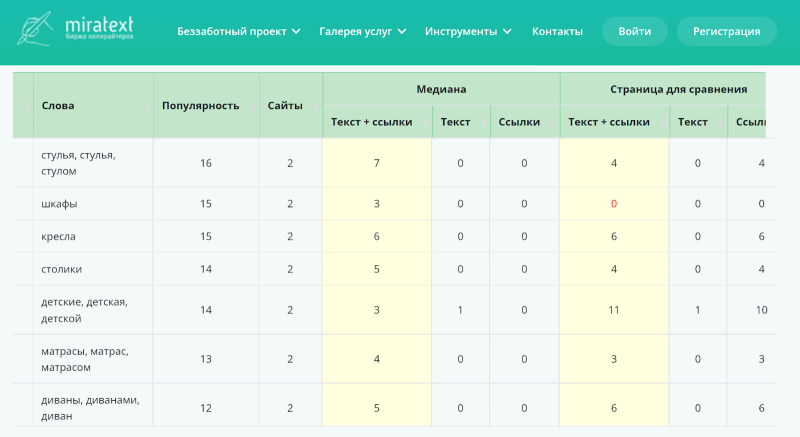
В таблице из инструмента «ГАР», которая составляется по результатам анализа, показаны слова, частота употребления, сравнение средней частоты употребления слов по ТОПу с вашей страницей и отмечены слова, которые не найдены на вашей странице, но должны быть:
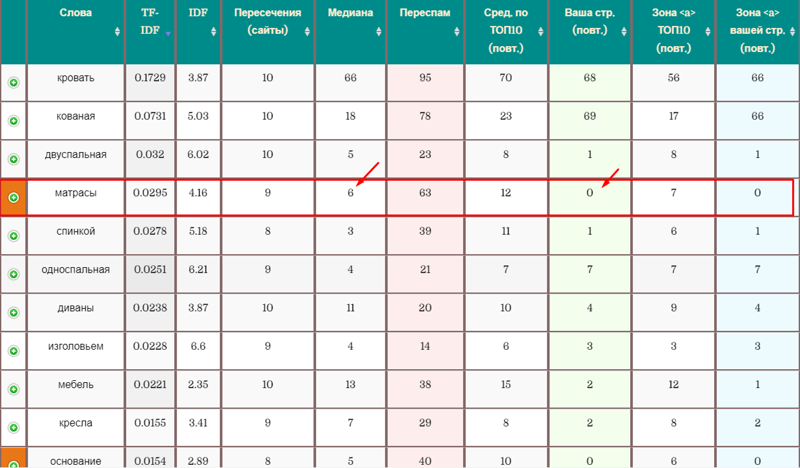
На страницах категорий обнаружился жёсткий переспам из-за того, что на втором уровне страниц отсутствовал листинг товаров.
SEO-специалисты, которые до этого работали с сайтом, пытались доработать количество вхождений главного ключа “кованые банкетки” с помощью ГАРа — у них тоже был доступ. По рекомендациям инструмента, нужно было 25 раз использовать слово «банкетки» и 30 раз слово «кованые». Поэтому эти слова просто зашили в текст.
Вот так:
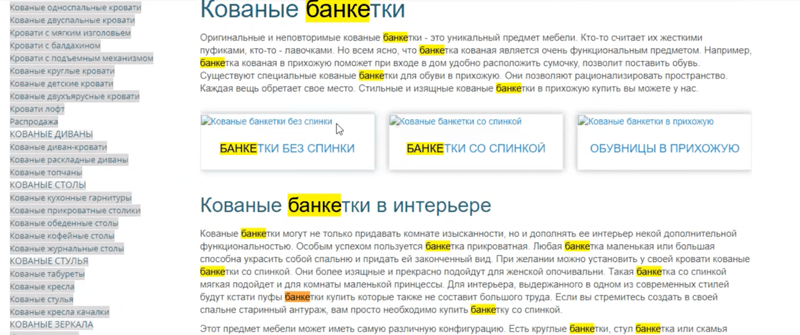
Видим, что слово «банкетки» упоминается почти в каждом предложении. Из-за этого произошёл переспам.
Если бы в категориях был листинг, то те же самые слова распределились бы по названиям товаров: «Кованая банкетка 001», «Кованая банкетка 002» и т. д.
По моему опыту, если «зашивать» тематические слова не через ссылки, а через текст, то Яндекс считает это переспамом и не пускает страницу в ТОП. В этом я убедился и при работе над сайтом «Идиллия металла».
Также переспам был и в сквозном меню — слова «кованые» и «кровати» повторялись в каждой категории и на каждой странице:

Та же история с меню слева:
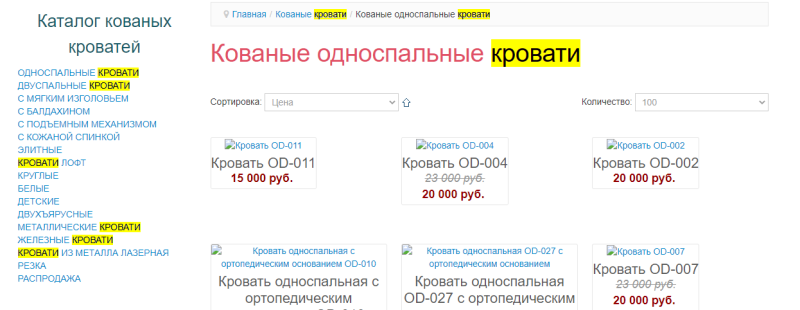
Слово «кованые» повторялось раз 100, слово «кровати» встречалось раз 150, к тому же на странице «Кованые банкетки». Зачем слово «кровать» на странице «Кованые банкетки»? Ни за чем.
Через ГАР я смотрел, сколько раз какое слово должно упоминаться на странице. Например, слово «кровать»:
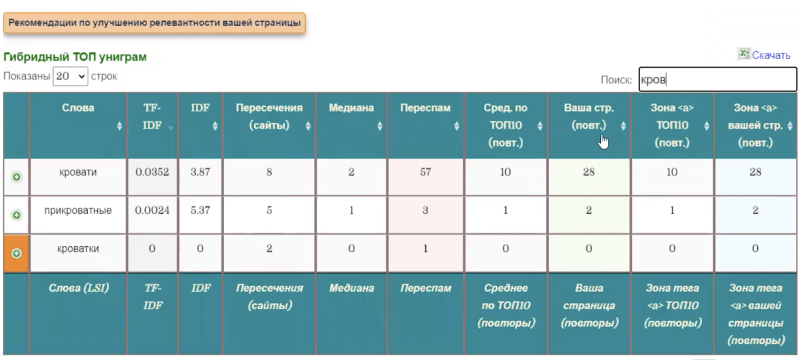
До того как я начал работать с сайтом, на странице «кованые банкетки» слово «кровать» упоминалось 28 раз, а, судя по анализатору, должно было только два раза.
Чтобы это исправить, я переработал меню в шапке, убрал слово «кованые». Остались только названия: «Кровати», «Диваны», «Столы» и т. д. Если нажать на категорию, то появляется «выпадайка»:
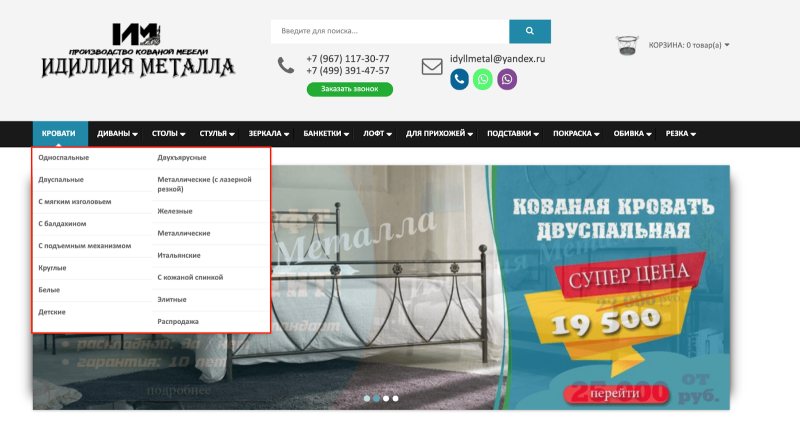
Так постепенно избавлялся от переспама.
Стратегии оптимизации перелинковки сайта
Цель стратегии оптимизации перелинковки – улучшение ссылочного графа в соответствии с типом сайта.
Наилучшая структура внутренних ссылок зависит от используемой бизнес-модели. Она может быть централизованной или децентрализованной в зависимости от того, на каких страницах возможна конверсия посетителей. Централизованные сайты обычно очень загружены контентом – например, SaaS, агентства или закрытые торговые площадки. Децентрализованные сайты (общедоступные маркетплейсы, потребительские сайты, социальные сети) легко масштабируются.
Стратегии оптимизации перелинковки децентрализованных сайтов
Основная цель для децентрализованных сайтов – обеспечить как можно больше релевантных связей между продуктами и категориями для увеличения продаж и поисковой видимости.
Ниже приведено множество примеров из сегмента электронной коммерции, но большинство из них также можно перенести на другие бизнес-модели.
Бестселлеры
Другие товары этого бренда
Горизонтальная таксономия
Большинство сайтов электронной коммерции по умолчанию используют вертикальную таксономию: категории продуктов, подкатегории и продукты. Горизонтальные таксономии – это бренды, места, события, личности и т.д.
Примером горизонтальной таксономии является категория Samsung Best Buy, которая ведет на несколько подкатегорий внутри Samsung.
Другой пример таксономии с горизонтальными ссылками можно найти на главной странице Target (обратите внимание на категории «Хэллоуин» и «Готовы к школе»).
Вместе с этим часто покупают
Пакеты продуктов – это один из лучших (а, возможно, и САМЫЙ лучший) способ семантически связать два продукта, которые тесно связаны друг с другом, но находятся в разных категориях.
Связанные категории
Стратегии оптимизации внутренних ссылок для контент-ориентированных сайтов
Разделение тем: идея заключается в том, чтобы в статьях чаще ссылаться на близкие по темам материалы и реже – на тексты по другим темам. То же самое можно сделать для товара в категории. Таким образом вы гарантируете, что текст ссылки останется актуальным, а статьи будут находиться в непосредственной близости друг к другу.
Эволюция разделения тем – это тематические кластеры. Такой подход предполагает статью, охватывающую короткое (основное) ключевое слово, а также короткие статьи (кластеры) для длинных ключевых слов, связанные и ссылающиеся на основное. Это позволяет создать тесные тематические отношения внутри ссылочной структуры.
Статьи по теме: Ссылки на статьи по теме внизу страницы должны использоваться на всех сайтах. Тем не менее, некоторые до сих пор о них забывают. Не совершайте эту ошибку! Оставляйте ссылки на близкие по теме сайты на с релевантными статьями.
Вот и все, друзья! Если вам кажется, что мы что-то упустили – расскажите об этом в комментариях, и мы обязательно дополним статью.
Нет плитки тегов
По технологии продвижения Антона Маркина, плитка тегов должна быть обязательно, потому что в неё можно вписать LSI-слова, которые должны быть на сайте. Так поисковик понимает, что это тематический сайт, и поднимает сайт в ТОП.
Кроме того, по моему опыту, плитка тегов увеличивает ПФ сайта естественным образом. А это важно, чтобы попасть в ТОП-10 Яндекса. Получается двойная выгода.
Как выглядит плитка тегов сейчас:

Я вручную создаю плитку тегов и «зашиваю» сюда необходимые LSI-слова. Например, смотрю через ГАР, что у меня не хватает пять раз слова «кровать» на какой-то странице. Иду и делаю там теги с этим словом.
Есть и другие инструменты для оценки LSI, например, Just-Magic. В него нужно добавить запрос, по которому хотите быть в ТОПе, например, “кованая мебель”, и он покажет, что слово «кованый» надо использовать такое-то количество раз с разными окончаниями: кованые, кованое, кованая.
ГАР и Миратекст показывают вообще все слова, которые необходимы на сайте, потому что есть теория, что Яндекс смотрит не только по фразе, например, “кованая мебель”, а вообще по всем тематическим словам:
Как показывает опыт, чем больше LSI-слов «зашито» в страницу сайта, тем более релевантен сайт в глазах Яндекса. Уточню, что большую часть LSI-слов лучше «зашивать» на самом сайте, а не в плитку тегов. Например, в названии товаров, в меню.
Я подходил к этому осторожно, потому что на нашем сайте меню сквозное, то есть отображается на всех страницах сайта. На одной странице слова из меню могут быть нужны, на другой — могут привести к переспаму. Нужно всё продумать.
Те LSI-слова, которые нельзя «зашить» на страницу, я добавлял в плитку тегов, в том числе в скрытую в самом конце страницы, чтобы пользователю она была не видна. Например, вот на этой странице:
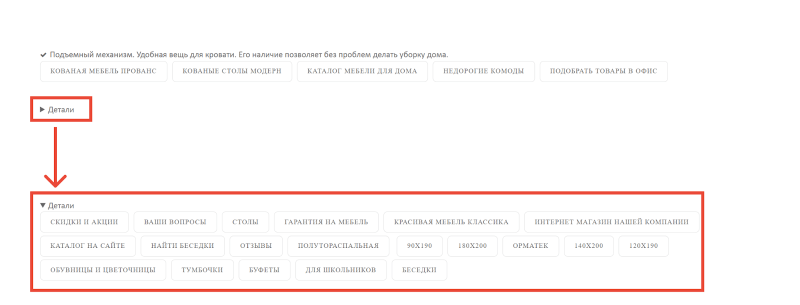
Страницы пагинации
Если у вас обширный каталог, то для удобства пользователей он разбивается на страницы. Это и есть пагинация.
Для скрытия страниц пагинации от индексации эффективней всего использовать атрибут rel=”canonical” тега </code>. В качестве канонической необходимо указывать основную страницу каталога.
Дополнительно обезопасить сайт от появления дублей страниц пагинации в индексе можно при помощи генерации уникальных метатегов title и description и заголовков h1 по следующему шаблону:
- [Title основной страницы пагинации] – номер страницы пагинации;
- [Description основной страницы пагинации] – номер страницы пагинации;
 Пример генерации title и description для страниц пагинации
Пример генерации title и description для страниц пагинации
- h1 основной страницы пагинации – номер страницы пагинации.
 Пример генерации h1 для страниц пагинации
Пример генерации h1 для страниц пагинации
При оптимизации страниц пагинации также нужно учесть два важных момента:
- Не стоит добавлять на страницы пагинации уникальные тексты. Это лишняя трата времени и денег — контент на этих страницах и так различается (разные товары). Дело не в уникальном контенте, а в том, что пользователю нет смысла попадать из поиска на 3-ю или 10-ю страницу каталога. Ему важно начать с начала, а потом он уже сам решит, двигаться дальше или нет.
- Если в интернет-магазине размещены SEO-тексты на категориях товаров, они должны отображаться только на первой странице, чтобы избежать дублирования контента.
Мы рассмотрели основные дубли. Но вариантов может быть множество. Главное — понимать, как они формируются, как с ними бороться и с помощью каких инструментов выявить.
Недоработанная структура
Проблема: структура была недостаточно проработана, отсутствовали некоторые нужные категории и блоки, было неудобно ориентироваться на сайте.
Решение: в момент разработки нового сайта я сделал прототип с новой структурой: проанализировал коммерческие факторы конкурентов и выстроил нужные на сайте блоки: поиск, телефоны, почта и др.
Прорабатывал структуру на основе анализа конкурентов. Собрал из ТОП-30 по ключевым запросам, посмотрел, что уникального есть в структуре каждого конкурента, и добавлял.
Для этого вбиваем запрос “кованые кровати” и смотрим, какие категории созданы под кровати. К примеру, двуспальные, полутораспальные, односпальные.
Это монотонная работа: открываешь каждый сайт и всё выписываешь. Выстраиваешь структуру, раскидываешь, в какую категорию или подкатегорию распределить. Получается самая большая структура, потому что ты собрал её со всех конкурентов.
Выписывал всё в XMind 8, программу для создания майнд-карты:

На мой взгляд, полная проработка структуры даёт рывок при начальном продвижении, потому что ты захватываешь низкочастотные запросы. Вывести сайт в ТОП по запросу “кованая кровать” тяжелее, чем вывести по запросу “односпальная кованая кровать”.
Когда ты собираешь огромное количество низкочастотных запросов — целевых и имеющих частоту — и прорабатываешь под них страницы, то у тебя начинает идти трафик на эти запросы с Яндекса.
Благодаря этому среднечастотные и высокочастотные запросы тоже начинают подниматься. Пользователи приходят на сайт по запросу “односпальная кованая кровать”, оставляют хороший ПФ, из-за этого улучшаются позиции запроса “кованые кровати”.
Результаты
Я ожидал, что выведу сайт в ТОП-10 по ключевым запросам за полгода, но получилось быстрее:
Переходы из поисковых систем:

Количество исключённых из индекса страниц уменьшилось. Сейчас их меньше 1 000, а было — 12,5 тысячи, над этим продолжаем работать:

Вот выборка со всех запросов. 89 % запросов находятся в ТОП-10 по Москве в Яндексе:
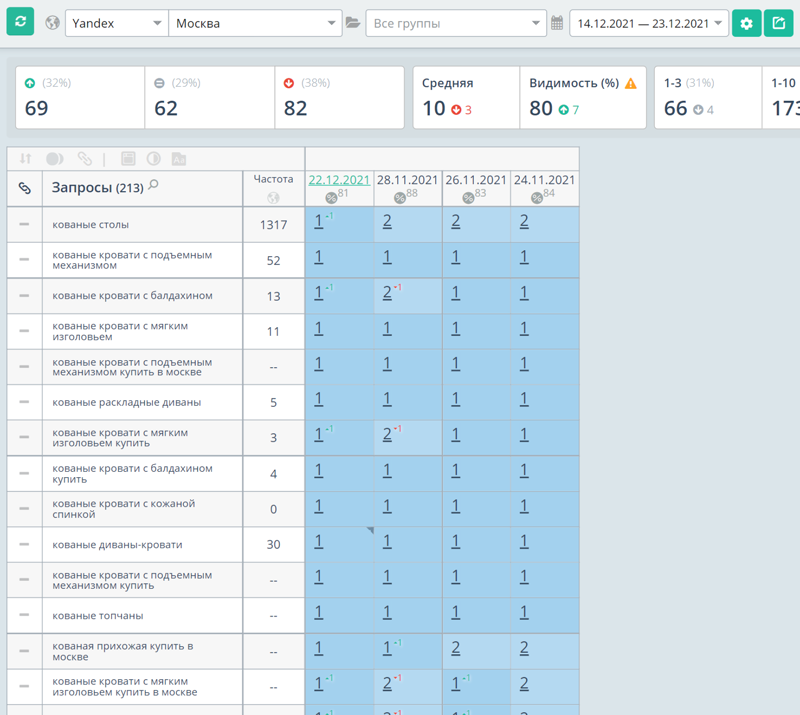
Дальше планирую добавить фильтрацию — возможность сортировки на странице с чек-боксами. За счёт этого появится больше LSI-слов. Буду продолжать прорабатывать страницы.
Как не допустить каннибализации запросов
Избежать каннибализации ключевых слов поможет строгая архитектура сайта. Создать каркас для будущей структуры поможет семантика, разбитая на кластеры: составьте майндмап или другую удобную схему с разделами по тематическим кластерам запросов. Эти кластеры помогут понять, какие страницы нужно создать. Отмечайте там существующие, чтобы не дублировать контент.
Если вы уже развиваете сайт и хотите реорганизовать структуру, придется составить схему из имеющихся страниц, и сопоставить страницы с кластерами семантики. Это будет сложно, если сайт большой и ветвистый с множеством разделов и подтем. Есть сервисы-помощники, к примеру, Balsalmiq поможет составить схему сайта.
Оптимизаторы обычно советуют выстраивать структуру по системе SILO — это многоуровневая система, с помощью которой легко управлять внутренним ссылочным весом. На сайте есть общие страницы категорий, в них есть отдельные темы, которые делятся на конкретные страницы.

Почитать по теме:
15 советов по seo-архитектуре сайта
Такая структура помогает поисковикам и пользователям ориентироваться в страницах и находить нужный релевантный контент.
Наложены ли на сайт фильтры
Чтобы проверить наличие фильтров, в Я.Вебмастере заходим на вкладку «Диагностика» → «Безопасность и нарушения». Здесь смотрим, есть ли фильтры, например, «Баден-Баден».
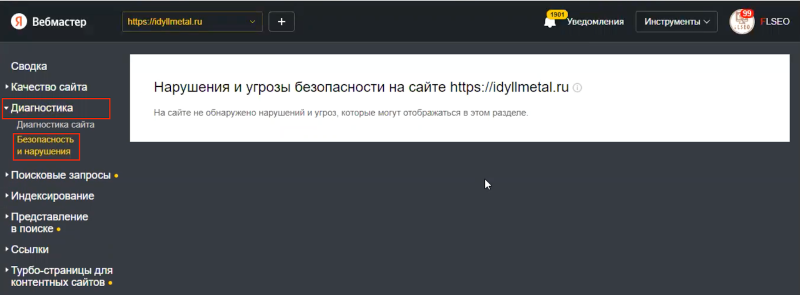
Примечание редакции
«Баден-Баден» — фильтр Яндекса, который опускает в поиске переоптимизированные и несодержательные страницы. Он бывает хостовый или запросозависимый / постраничный. В Вебмастере можно отследить только хостовый «Баден-Баден».
Бывает так, что в Я.Вебмастере не отображается «Баден-Баден» за переспам, а сайт всё равно занимает низкие позиции из-за переспама. Как проверить, что дело именно в переспаме?
Нам поможет сервис «Тургенев», который показывает, насколько текст переспамлен и как это доработать:
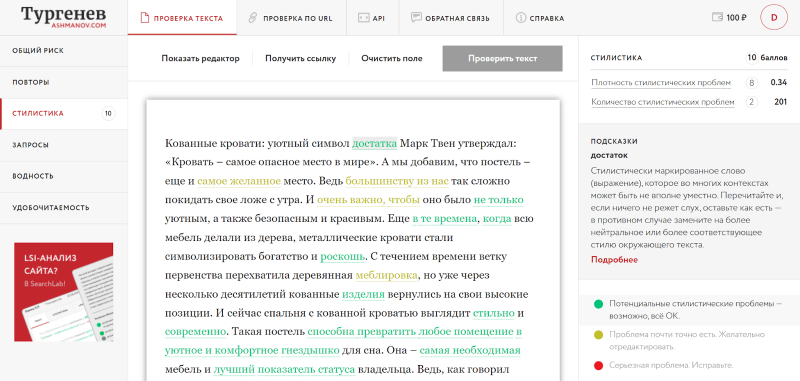
Как показывает мой опыт, если исправить тексты, то через 2–3 месяца сайт снова будет занимать высокие позиции. У «Идиллии металла» фильтра не было, но переспам по текстам всё-таки был.
Что такое pagerank?
PageRank – это алгоритм, который оценивает важность веб-страницы на основе релевантности и авторитета ссылок, указывающих на нее с других сайтов. Он назван в честь своего создателя Ларри Пейджа.
Основной принцип – рассматривайте обратные ссылки (ссылки с других сайтов) как «голоса». Чем больше голосов у страницы, тем выше она поднимается в результатах поиска. Имейте в виду, что при ранжировании документов Google учитывает множество факторов, и обратные ссылки – лишь один из них.
Google больше не использует классическую формулу расчета PageRank, хотя она до сих пор в той или иной степени влияет на ранжирование. Раньше PR любой страницы можно было узнать с помощью специальных дополнений к браузеру, но в 2022 году эту возможность упразднили.
Другими словами, простым пользователям больше не доступен реальный PageRank страницы. Однако, можно использовать сторонние инструменты, чтобы определить показатель, наиболее близкий к традиционному PageRank. Эти проприетарные метрики называются авторитетом домена (Domain Authority от Moz), силой страницы (Page Strength от SEMrush) или рейтингом домена (Domain Rating от Ahrefs).
Можно сказать, что концепция PageRank сделала Google тем, чем он является сегодня: самым успешным стартапом в истории. За прошедшие годы поисковой гигант зарегистрировал множество патентов, по которым можно отследить эволюцию PageRank.
Патенты PageRank:
Товары с мало отличающимися / близкими характеристиками
У таких товаров, как правило, описание просто дублируется, либо частично отличается, например, дополнительным словом или небольшим предложением.
Попробую привести наглядный пример: магазин продает одежду, в карточке одного товара появляются вариации – размера или цвета, например. Практически одинаковые или схожие описания для разных товаров – это не очень хорошо:
Одно описание для разных размеров / цветов / вариантов:
Краулер, с высокой долей вероятности, просто запутается – обойдет первую карточку товара, а схожие (с разными размерами, цветами, материалами) оставит без внимания. Решение простое: все повторяющиеся предложения (на страницах со схожим контентом) просто берем в следующий тег:
Подводные камни такого решения: данный тег учитывает только «Яндекс», кроме этого он не подходит для отличающихся характеристик товара.
Еще один вариант решения проблемы схожих описаний: использовать селектор, чтобы выбирать различные характеристики товара. CSS-селектор определяет с каким именно элементом соотносится выбранное CSS-правило. Предварительно нужно будет сгруппировать все схожие типы товаров, в рамках единой карточки, например, если мы говорим об интернет-магазине.
Третий вариант: все описания схожих предметов нужно сделать максимально уникальным. Если таких карточек слишком много, то начните с тех, которые приносят наиболее высокие конверсии. Например, уникализируйте описания футболок только красного цвета, а зеленые и розовые оставьте на потом, если их не покупают. В общем, правильно расставляйте приоритеты.
Как найти дубли на своем сайте
Для выявления дублированного контента на своих сайтах, я использую несколько инструментов. Вообще искать можно и вручную, но, если страниц много, то этот вариант трудно исполним. Гораздо легче находить дубли при помощи специализированных сервисов, таких как NetPeak Spider.
Теперь указываем домен своего сайта и выбираем пункт «Старт». После того как сканирование будет завершено, выбираем «Отфильтрованные результаты», открываем раздел «Отчеты» и в пункте «Ошибки» находим все интересующие нас дубли: страниц / текста / Title / Description:
Отмечу, что прорабатывать нужно только те дубли, которые отдают 200-ый код.
Также для автоматического поиска дублей можно использовать программу Screaming Frog SEO Spider: достаточно указать домен и запустить сканирование. В результатах поиска нужно выбрать пункт URL. Дублирование контента выводится в разделе Duplicate:
Ну и, конечно, дубли покажет «Яндекс.Вебмастер» и Google Search Console. В первом случае идем в пункт «Страницы в поиске», который находится в разделе «Индексирование». Теперь обращаем внимание на пункт «Статус и URL». Здесь будут отображаться все найденные дубли:
В GSC дублированный контент обнаружить не составит труда. Достаточно открыть раздел «Покрытие». Здесь обращаем внимание на пункт «Сведения» и в поле «Статус» смотрим лист исключенных URL.
Как внутренние ссылки помогают seo
Внутренние ссылки не только полезны для простых пользователей, но и распределяют PageRank по всему сайту, помогая поисковым роботам находить все релевантные страницы домена. Теоретически, чем выше PageRank страницы, тем выше она располагается в поисковой выдаче.
PageRank – это лишь одна из многих метрик для ранжирования. Основная цель оптимизации внутренних ссылок заключается в привлечении органического трафика на сайт.
Эта информация больше недоступна, но в документации Search Console упоминается, что внутренние ссылки – это сигналы относительной важности страницы для Google (статья на SearchEngineLand).
Мэтт Каттс подтвердил это в интервью для Stone Temple (ныне Perficient):
«Нет жесткого ограничения на сканирование. Правильнее всего считать, что количество страниц, которые сканирует робот, примерно пропорционально показателю PageRank. Следовательно, если на вашей корневой странице много входящих ссылок, мы обязательно их просканируем. Она может ссылаться на другие страницы, которые получат оценку PageRank, а мы просканируем и их. Однако, чем дальше вы углубляетесь в свой сайт, тем ниже становится рейтинг PageRank в большинстве случаев».
Мэтт Каттс
Почему появляются дубли
Самые частые причины дублирования контента:
- Не настроено перенаправление.
- Пагинационные страницы.
- Слэш (как отсутствие, так и присутствие) в конце ссылок.
- Карточки похожих товаров.
- Особенности CMS.
Самая главная причина – это техническое несовершенство абсолютно всех CMS, которые автоматически генерят дубли во множестве ситуаций. Самый частый случай – соотнесение одной веб-страницы одновременно с двумя (и более, соответственно) рубриками на сайте.
Так могут выглядеть дубли, создаваемые системой управления контентом:
Именно сама CMS представляет наибольшую опасность, когда мы говорим об автогенерации URL и возникающим дублировании контента.
Дублями очень часто грешат и плагины для CMS, особенно – плагины для WordPress. Когда мы говорим о дублях в технических разделах сайта, то наиболее часто портачит Joomla и всеми любимый Bitrix. Указанные CMS автоматически создают ссылки, включающие специальные параметры.
Выглядят параметрические URL следующим образом:
Многие CMS также грешат зацикливанием URL, которое происходит автоматически. Большое количество таких ссылок затрудняет работу краулеров и негативно сказывается на индексации домена.
Есть ли привязка к яндекс.бизнесу
Когда сайт вне ТОП-50, нужно проверить и его привязку к Яндекс.Бизнесу. Для этого в Я.Вебмастере переходим в «Представление в поиске» → «Региональность».
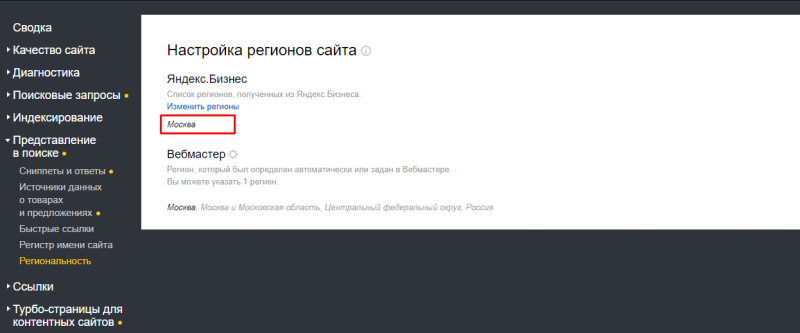
Через эту привязку Яндекс определяет, выводить ли сайт в нужном регионе. Например, если не привязать регион «Москва», то по запросу «кованая кровать» Яндекс может не вывести сайт в Москве.
Почему? Запрос “кованая кровать” Яндекс почти всегда считает как геозависимый с коммерческим интентом и показывает в выдаче магазины, которые продают кованые кровати в вашем регионе. Если регион не привязан, то и сайт по геозависимому запросу выводиться не будет; а если и будет, то на очень низких позициях.
Интернет-магазин можно будет найти исключительно по запросу “кованая кровать в Москве”, то есть по запросу с указанием конкретного региона, потому что у нас есть такая посадочная; но без указания региона — маловероятно. А пользователи чаще всего пишут запрос без указания региона.
Так что город обязательно должен быть привязан к Яндекс.Бизнесу и иметь активную карточку в Яндекс.Картах. У «Идиллии металла» это было.
Что такое cheirank?
CheiRank измеряет важность страницы на основе исходящих ссылок. Это противоположность PageRank, с помощью которой можно оценить, насколько коммуникативным является веб-узел. Объясню это понятие простыми словами: если цель PageRank заключается в измерении «силы» входящих ссылок на страницу, то цель CheiRank – измерение силы исходящих ссылок со страницы.
Обратите внимание, что важность CheiRank относительна. Обычно его сравнивают со всеми страницами домена. Вы можете использовать его, к примеру, для определения важных страниц-хабов. Иными словами, «коммуникативность» можно рассматривать как количество исходящих ссылок на странице.
Оптимизация CheiRank порой вызывает сложности, поскольку идеального значения не существует. Однако, есть оптимальное значение для определенного контекста. Наилучшая структура внутренних ссылок зависит от вашей бизнес-модели.
Чтобы понять, что именно представляет из себя этот показатель, взгляните на скриншот выше. Это отрывок из анализа, который я провел много лет назад, когда еще работал в Atlassian. В нем с помощью краулера оцениваются PageRank и CheiRank. Эти метрики помогли нам оптимизировать маркетплейс и значительно увеличить трафик.
Если нет времени/опыта разбираться с дублями
Если у вас нет времени на то, чтобы разобраться с дублями, закажите аудит сайта — помимо наличия дублей вы получите массу полезной информации о своем ресурсе: наличие ошибок в HTML-коде, заголовках, метатегах, структуре, внутренней перелинковке, юзабилити, оптимизации контента и т. д.
Еще один вариант — запустить поисковое продвижение сайта в SEO-модуле PromoPult. Специалисты системы выполнят более 70 видов работ по оптимизации сайта (в том числе устранят дубли). В итоге вы получите привлекательный для пользователей сайт, который будет стабильно расти в поиске и получать бесплатный трафик.
Как разграничить интенты
В одном из выпусков рубрики «Спроси PR-CY» пользователь спросил, как разграничить коммерческие и информационные запросы в рамках одного сайта, чтобы не было каннибализма индексируемых страниц в SERP.
Эксперт Ксения Пескова, SEO-TeamLead Siteclinic, дала совет, как разграничить интенты:
- Не смешивайте запросы разных интентов на одной странице.
- Следите за текстом анкора при размещении внешних и внутренних ссылок.
Например, страницу услуг можно оптимизировать под одну группу запросов, которая будет включать ключевые слова «вывоз мусора Москва», «вывоз мусора», «вывоз мусора цена». А под информационную группу запросов «куда вывозят мусор из Москвы» можно оптимизировать отдельную посадочную информационную страницу.
Чтобы не сталкиваться с такой проблемой и не искать каннибализационные страницы, лучше изначально следить за структурой сайта и релевантностью страниц запросам. Если у вас много страниц дублируют друг друга, пересмотрите подход к созданию нового контента.
Способ 2. яндекс.вебмастер
Сообщения о дублях страниц, которые обнаружил на сайте робот Яндекса, появляется в разделе «Диагностика». Например, так выглядит уведомление о страницах с одинаковыми title и description:
Также Яндекс предупредит о наличии на сайте страниц с незначащими GET-параметрами.
Примеры страниц с одинаковыми тегами title и description собраны в разделе «Индексирование» / «Заголовки и описания»:
При наличии дублей метатегов, здесь будет информация о количестве затронутых страниц (это же уведомление будет в разделе «Сводка»), примеры и рекомендации по исправлению. Таблицу с URL можно выгрузить в форматах XLS и CSV.
Разумно не ждать уведомлений и самостоятельно выявить дубли страниц с помощью Вебмастера. Алгоритм несложный:
- Перейдите в раздел «Индексирование» / «Страницы в поиске»:
- Активируйте вкладку «Все страницы» и выгрузите отчет в формате XLS:
- Пройдитесь по списку и найдите «подозрительные» URL. Для удобства активируйте фильтры по частям URL, указывающим на дублирование.
Не удалять страницы товаров
Нельзя удалять страницы товаров. Во многих интернет-магазинах мы можем попасть на товар, которого нет в наличии или он снят с производства. Обычно их размещают в самом низу листинга, но не удаляют. И это правильное решение.
Яндекс не определяет, есть ли этот товар в наличии или нет. Он просто видит, что это внутренняя ссылка на товары этой категории и считывает его, как товар из этой категории.
Есть мнение, что это может ухудшать поведенческие факторы, но, на мой взгляд, всё как раз наоборот. Пользователь приходит, кликает на товар, которого нет в наличии, смотрит, что есть похожего в рекомендуемых, переходит туда и т. д. Так естественным образом растёт ПФ. По крайней мере, какого-то негативного влияния я не замечал.
А вот удаление страниц может негативно сказаться на позициях. Я экспериментировал. Когда у сайта со временем количество страниц увеличивается, то для Яндекса это хороший знак. А вот если количество страниц уменьшается, то позиции в Яндексе могут и просесть.
Какие страницы в поиске
Для этого заходим в кабинет Я.Вебмастера, «Индексирование» → «Страницы в поиске». Смотрим, какие страницы удалялись / не удалялись. Затем смотрим, сколько страниц Яндекс исключил из поиска. Для этого кликаем на иконку «Исключённые»:

На скриншоте видно, что на сайте было больше 12,5 тысячи страниц, которые Яндекс исключил из поиска. При том, что всего на сайте существует 3–4 тысячи страниц. До сих пор я продолжаю с этим бороться:

Способ 3. парсинг проиндексированных страниц
При отслеживании индексации в панели Яндекса проблематично сопоставить данные с Google — приходится вручную перепроверять, проиндексирован ли здесь дубль. Избежать такой проблемы позволяет парсер проиндексированных страниц от PromoPult.
Что нужно сделать:
В этом примере страницы пагинации проиндексированы и Яндексом, и Google. Решение — настроить канонизацию для страниц пагинации и по возможности уникализировать метаданные.
Используя парсер от PromoPult, вы поймете, дублируются страницы в обоих поисковиках или только в одном. Это позволит подобрать оптимальные инструменты решения проблемы.
Некорректное название товаров
На сайте была и ошибка в названиях: товары назывались не так, как их гипотетически будет искать пользователь. Например, пользователь вводит запрос “кованая банкетка”, но на сайте все товары называются просто «Банкетка».
До этого мы убирали слово «кованый» из меню и категорий, чтобы избежать переспама. Но после этого я увидел в ГАР, что теперь у меня недостаточное вхождение слова «кованый». Оно должно упоминаться на странице ещё 40 раз. Я добавил его в названия товаров «Кованая банкетка BN-003», «Кованая банкетка BN-009» и так далее. Так я обеспечил достаточное количество вхождений, и товары стали называться так, как их на самом деле ищет пользователь:
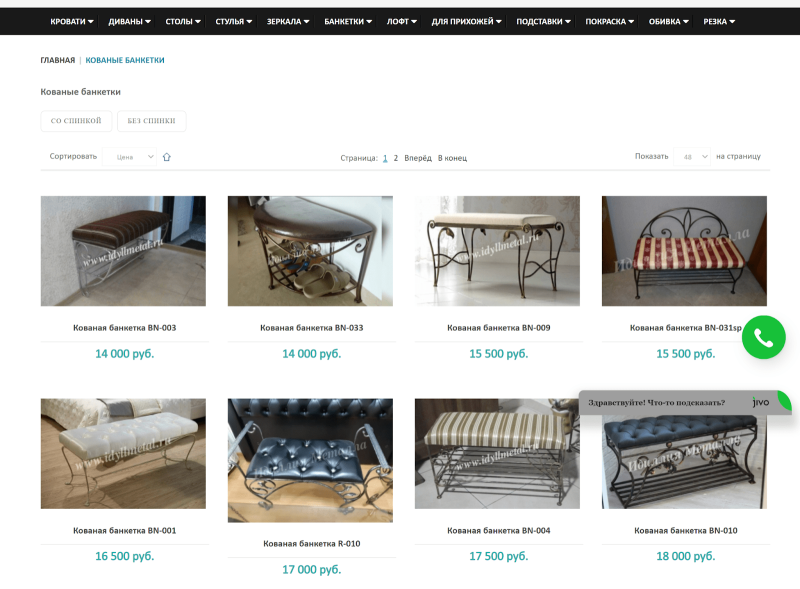
В чем опасность дублированного контента
Здесь можно назвать целый ряд неприятных последствий. Среди них
- высокий риск пессимизации одной страницы и целого домена;
- затруднение при индексировании новых страниц сайта;
- проблемы с внешними URL;
- утрата позиций в SERP;
- дубли в результатах поиска – нередки случаи, когда дублирующая страница полностью замещает оригинал и встает на его место в SERP.
Неявные дубли могут стать причиной снижения общей уникальности текста на странице. Особенно это характерно для широко тиражируемого контента, например – новостей.
При отсутствии контроля за дублями, создаются дополнительные временные затраты при переобходе всех страниц. Дело в том, что у каждого краулера существует определенный лимит запросов к вашему домену. Вполне реальны случаи, когда краулер тратит все лимиты при обходе мусорных страниц, а до страниц с оригинальным контентом так и не добирается.
Лучшие методы оптимизации внутренних ссылок
Давайте рассмотрим несколько основных методик оптимизации внутренних ссылок.
Исправление или удаление нерабочих ссылок
Нерабочие ссылки – плохой опыт как для пользователей, так и для поисковых систем. Короче говоря, вы должны избегать ссылок на страницы с кодом состояния, отличным от 200.
Google говорит об этом Руководстве по SEO: «Не допускайте устаревания навигационной страницы из-за неработающих ссылок».
Мой совет: трудно предотвратить появление нерабочих ссылок для крупных сайтов, но от них стоит избавляться. Вы можете найти их с помощью различных утилит, в том числе и с помощью SiteAnalyzer.
В здоровой структуре сайта должно быть как можно меньше ссылок с кодом статуса, отличным от 200 (см. изображение ниже).
Оптимизация анкоров для внутренних ссылок
Страница для печати
Дам пример для наглядности:
Как видим из примера выше, дубли появляются в случае, когда печатная версия страницы на вашем сайте, генерируется при помощи функции ?print. Такая версия страницы печати – всегда дубль, так как ее содержимое полностью идентично оригинальной версии страницы.
Решить проблему дубля печатной страницы можно при помощи уже знакомых нам директив: Clean-param и Disallow. Первую директиву понимает исключительно отечественный поисковик. Вторая создана специально для краулеров Google. Соответствующие директивы необходимо прописать роботс-файле. Например, так мы сделаем это для всех краулеров:
Вышеуказанное правило будет работать для всех поисковых систем. Если же вам нужно ограничить индексирование print-страниц только краулерам «Яндекса», то воспользуйтесь Clean-param, если только роботам Google – применяйте директиву Disallow.
Прорабатывать широкую структуру
Я заметил, что Яндекс смотрит не только на основную категорию, но и на смежные. Это особенно важно для интернет-магазинов.
Например, есть запрос “купить шкаф”. Если на сайте будет хорошо проработана категория «Шкафы», но не будет хорошо проработанной категории «Столы», то по запросу “купить шкаф” Яндекс не пропустит сайт в ТОП.
Многие интернет-магазины делают упор только на одну категорию, самую прибыльную. А в других категориях создают максимум одну страницу или вообще их не трогают.
Мой опыт показывает, что в этой нише нельзя пробиться в ТОП, если у магазина недостаточно ассортимента. Например, если вы продаёте только шкафы, то, конечно, категории «Столы» у вас быть не может. Поэтому конкурировать за ТОП с крупными магазинами вы не сможете.
Для Яндекса важно проработать широкую структуру.
Дубли
Проблема: одни и те же товары и подкатегории могли размещаться на сайте под разными ссылками в разных категориях. Это давало множество дублей. После переработки структуры надо было удалить дубли, которые уже имелись на сайте.
Решение: чтобы ускорить процесс удаления, пользовался инструментом Я.Вебмастера «Удаление страницы из поиска».
Каждый день я закидывал по 500 страниц. Насколько я знаю, это максимум страниц, которые можно отправить на удаление за один день в Я.Вебмастере. Если бы я этого не делал, то процесс затянулся бы ещё на несколько месяцев.
Некоторые страницы удалялись очень долго, иногда Вебмастер просто зависал, оставлял статус «В процессе» или «Отклонено». Получается, что на сайте их уже не было, при переходе они выдавали ошибку 404, а из поиска Яндекс их не удалял.
Что было на старте
Мой клиент — интернет-магазин кованой мебели «Идиллия металла». Он пришёл ко мне в начале июля 2021 года с проблемой, что сайт несколько лет не может попасть в ТОП Яндекса.
Как выглядел сайт до начала работ — Вебархив.
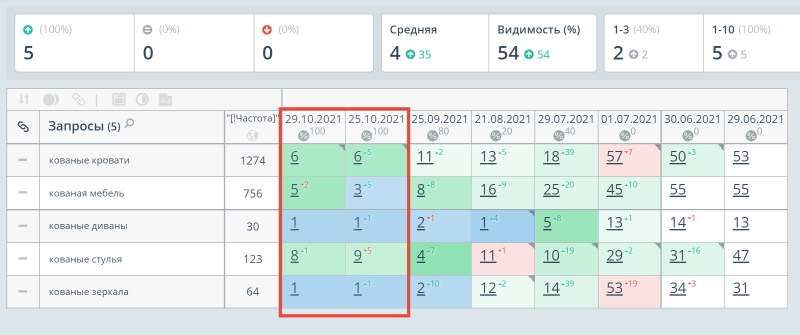
Сначала я посмотрел в Топвизоре позиции сайта по самым важным для нас ключевым запросам: “кованые кровати”, “кованая мебель”, “кованые диваны”, “кованые стулья” и “кованые зеркала”. Заказчику я давал гарантии, что смогу вывести в ТОП-10 именно эти запросы, поэтому на них и ориентировались.
Полная семантика включала в себя около 200 запросов. Позиции проверяли в Яндексе по региону 213 «Москва».
Как исправить каннибализацию запросов
- Объединить страницы в одну
Если несколько конкурирующих страниц несут ценный контент и имеют свои ссылки, перенесите важный контент на самую сильную из них, и настройте на нее 301 редирект с остальных. - Удалить неважные
Если страницы не полезны аудитории и не имеют своих ссылок, оставьте одну самую сильную, а остальные удалите. - Сосредоточьтесь на целевой
Если не хочется ничего удалять, выберите одну целевую страницу, а на остальных уменьшите число вхождений в тексте и мета-тегах, поставьте с них ссылки на целевую страницу. Их можно заточить под низкочастотные запросы и обновить контент, чтобы страницы были полезны для клиентов.
Слэш после url
Возможно, вы не обращали внимания, но на разных сайтах используется два типа адресов – с косой чертой в конце адреса и без нее. Выглядит это следующим образом:
Косая черта в конце адреса – одна из самых частых причин дублей. Решить эту проблему не сложнее, чем предыдущие – достаточно сделать 301-ое и перенаправление. О том, как именно это сделать, вы можете узнать в блоге TexTerra.
Что касается более предпочтительного варианта – оставлять все ссылки со слэшем в конце или без него, то здесь нужно смотреть на то, каких URL у вас на сайте было больше изначально. Если со слэшем – значит, оставляем URL со знаком / в конце, если наоборот – оставляет URL без /.
В чем заключается разница между внутренними и внешними ссылками?
Внутренние ссылки перенаправляют пользователя на страницы в том же домене, на которых они расположены, в то время как внешние ссылки ведут на страницы других доменов.
Разница между внутренними и внешними ссылками очевидна, но многие часто забывают, что они тесно взаимосвязаны. Как я писал в прошлых статьях:
Все знают, что PageRank – один из важнейших SEO факторов ранжирования, но мы часто забываем, что он распределяется между исходящими ссылками! Многие оптимизируют внутренние ссылки без учета обратных ссылок. Подобный подход может привести к принятию неэффективных решений.
Существуют исходящие и входящие ссылки.
Внутренние ссылки влияют на PageRank так же, как внешние.
Способ 1. «ручной»
Зная особенности своей CMS, можно быстро вручную найти дубли в поисковиках. Для этого введите в поисковой строке такой запрос:
site:{ваш домен} inurl:{фрагмент URL}
Например, мы знаем, что на сайте URL страниц пагинации формируются с помощью GET-запроса ?page=. Вводим в Google запрос и находим 4 дубля:
Также мы узнали, что в дублирующихся страницах встречаются запросы ?limit=, ?start=, ?category_id= — по ним тоже стоит проверить сайт на наличие дублей.
То же самое делаем в Яндексе (здесь уже 18 дублей):
Этот способ хорошо подходит для экспресс-анализа сайта. Для системной работы используйте другие способы.
404-ая
Один из самых частых сценариев неочевидного дублирования – это некорректно настроенная 404-ая страница. В таких условиях, любая страница будет выводить одинаковый для всех шаблон, отдающий 200-ый код ответа сервера.
Обратите внимание на то, как именно настроена 404-ая на вашем сайте. Помните – чтобы избежать дублей 404-ой, необходимо обратить внимание на все проблемные страницы. Они должны отдавать исключительно 404-ый код.
Еще один вариант решения этой проблемы – просто настроить редирект на страницу с информацией, которую искал посетитель.
Www в ссылках
По аналогии со слэшем, отличаться URL могут и по отсутствию или наличию «www» в начале адреса. На практике такой URL может выглядеть следующим образом:
Избавиться от дублей адресов по признаку наличия или отсутствия «www» можно несколькими способами. Для начала определитесь и укажите главное зеркало. В блоге есть целая статья на эту тему. Статья старая, но в целом актуальная. Единственное замечание – в роботс больше не нужно указывать host-директиву.
Типы внутренних ссылок
Есть два типа внутренних ссылок: контентные и модульные. Контентная ссылка – это простая ссылка в основном содержимом страницы (см. желтое поле на рисунке ниже).
Модульные ссылки используются в различных элементах навигации – к примеру, в хедере и футере страницы, а также в связанных статьях (оранжевые поля на скриншоте выше). Связывание модулей позволяет более систематически настраивать внутренний ссылочный граф сайта. Такой способ проще масштабировать в сравнении со ссылками в основном содержимом.
Делать страницы товаров уникальными
У интернет-магазинов частая проблема — недостаточно качественные страницы (малоценные или маловостребованные).
Нужно следить, чтобы страницы товаров были уникальны. Делать блок «Рекомендованные товары», «Похожие товары» и т. д. Следите, чтобы сопутствующие товары не были одинаковыми на каждой странице, а выводились рандомно всегда.
Например, изначально на сайте «Идиллия металла» были рекомендованные товары, но одинаковые на каждой странице — это только ухудшало ситуацию с уникальностью.
Что такое каннибализация запросов и почему это проблема
Каннибализация запросов — это ситуация, когда несколько страниц одного сайта оптимизированы под одно и то же приоритетное ключевое слово и соперничают за место в топе. Поисковые системы должны определить, какая из этих страниц качественнее и релевантнее поисковому запросу.
Было бы здорово оптимизировать, например, пять страниц под один запрос и занять ими пять строчек выдачи. Но скорее всего поисковик выберет одну страницу, причем это может быть не та, какую вы бы хотели видеть в топе.
Еще интересные статьи о бумаге:
 Бизнес на светильниках и люстрах | Делай деньги
Бизнес на светильниках и люстрах | Делай деньги Как использовать утюг, пресс и другие инструменты для разглаживания смятой бумаги?
Как использовать утюг, пресс и другие инструменты для разглаживания смятой бумаги? Ламинационная пленка, изготовление и применение
Ламинационная пленка, изготовление и применение Стандартные размеры фотографий для печати: небольшой обзор
Стандартные размеры фотографий для печати: небольшой обзор The history of paper. | Useful article about paper – Snow Maiden.
The history of paper. | Useful article about paper – Snow Maiden. Разрешение изображений и качество печати | Photoshop
Разрешение изображений и качество печати | Photoshop Изменение размер изображения или фото онлайн – Это очень просто, это бесплатно!
Изменение размер изображения или фото онлайн – Это очень просто, это бесплатно! Виды кальки и ее использование
Виды кальки и ее использование